Deep learning. By this point, we’ve all heard of it. It’s the magic silver bullet that can fix any complex problem. It’s the special ingredient that can take any bland or rudimentary analysis and create an immense five course meal of actionable insights. But, what is at the core of this machine learning technique? Is it truly something that all companies need to invest in? Will implementing it bring immediate business value and create forever-increasing ROI? Or, is this some type of elusive marriage masked by marketing hype? Before even considering these questions, we need to take a step back and accurately define what deep learning is.
What is Deep Learning?
From a practical standpoint, we can say that deep learning is a machine learning technique that aims to map a set of inputs to a set of outputs by utilizing a multi-layered neural network. This network tries to replicate the way the human brain processes information by learning from large amounts of example data. As information flows through the network, special attributes, called weights, are tweaked and updated during the training period to move the network into its most accurate state. One of the more basic types of neural networks, often called a feedforward network, is shown below.
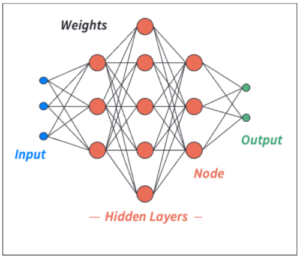
Figure 1: A simple feedforward neural network comprised of 3 hidden layers. The input layer in blue relates to the features, or predictive variables. The output layer in green relates to the target variable, or dependent variable. Weights represented in black determine how much emphasis is given to the preceding layer’s information. Hidden layers in red are made up nodes, or units, that aggregate preceding layer information through a linear combination of weights and preceding nodal values.
The input layer is a collection of nodes, sometimes called units, that correspond to the features, or predictive variables, in the dataset. The output layer represents the target variable and can be multi-nodal, in the case of classification, or have a single node for regression. Layers that aren’t considered input or output layers are called hidden layers.
Each hidden layer in a neural network is made of special aggregation nodes that combine information from the preceding layers and help capture interactions between predictive variables. Information is passed sequentially from layer to layer using these aggregation nodes. Connections from each layer to the next are formed through the concept of weights (the black lines in teh above image). These weights indicate how strongly the information of the starting layer affects the nodal output at the aggregation layer.
This process of moving data through a network is often called forward propagation, or a forward pass. Neural networks make predictions by passing information sequentially through their layers and performing many matrix multiplication and aggregation operations. Once a prediction has been made, the network must determine the accuracy of its results. This is often done with the use of a loss function (sometimes called a cost function). The error in the network determined by the loss function is passed backward (propagated) into the network moving from the output layer toward the input layer. During this back propagation process, the gradients of each weight are calculated and used to update the network’s internal state. This update is performed in such a way that each weight will take a small, incremental step in the direction that yields the most accurate model. The images below show simplified versions of the forward propagation and backpropagation techniques.
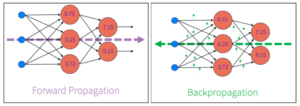
Figure 2 (left): Simplified example of a forward pass in a neural network. Forward propagation is used to create a prediction in neural networks by passing information sequentially from the input layer, through all hidden layers, and ending with the output layer. Internal nodal values for hidden layers are determined by the aggregation operations performed during the forward pass.
Figure 2 (right): Simplified example of backpropagation in a neural network. Once a forward pass has been performed, and internal nodal values are calculated, the error associated with the network’s prediction can be evaluated via a loss function. This error can be used to calculate gradients of each weight within the network and update each weight to move the network to the most accurate state possible.
One of the more powerful aspects of neural networks is their unique ability to capture non-linearity in datasets. This is done through an attribute called an activation function. In the previous examples, the aggregation points of a layer were described as a linear combination of weights and preceding layer information. Having a network defined in this way is completely fine — if the relationship between features and weights is always linear. Activation functions are applied to network layers with hopes of capturing non-linearity in the data. An example of one of the most popular activation functions, ReLU (rectified linear unit), is shown below.
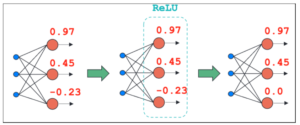

Figure 3: Simple example of one of the most popular activation functions, the rectified linear unit (ReLU), acting on a single hidden layer within a neural network.
Notice that the ReLU activation function is applied to all nodes in the hidden layer, after aggregation has been performed. The resulting nodal values are transformed based on the activation function and will be used by proceeding layers for additional aggregation operations. There are many activation functions that can be used in neural network designs (tanh, relu, elu, sigmoid, softmax). The important thing to remember is that these activation functions allow networks to capture non-linear trends in data.
While having the ability to capture non-linearity is a powerful attribute of deep learning models, perhaps the most distinguishing feature of these models from other machine learning approaches is their ability to perform feature extraction on their own.
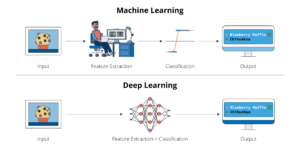
In traditional machine learning approaches, a human is tasked with developing predictive and useful features for a model through a process called feature engineering. Once these features have been created, further processes may be used by the human to select and extract the most meaningful set of features that best represent the underlying mechanism of the data. The beauty of deep learning models is that they learn useful representations from the data themselves instead of making a human explicitly engineer those representations. This fact makes deep learning extremely attractive to fields that require complex feature engineering or might even need features to be expressed in a way that is unknown or unobservable in the real world.
But is all of this worthwhile to know? Is deep learning really a concept that you should care about?
Why Should I Care About Deep Learning?
Deep learning has proven capable of solving many advanced problems in the scientific and engineering ecosystem. Recently, Google’s DeepMind released AlphaFold that provides a solution to a 50-year old “protein folding” challenge. GitHub and OpenAI have partnered to launch GitHub Copilot, an AI pair programmer that suggests individual lines of code and whole functions based on context from comments and surrounding code. Furthermore, deep learning has extended into other areas and proven successful in industries like human translation, healthcare, autonomous vehicles and robots, pattern recognition, and image classification.
It’s important to remember that deep learning is a technique for solving problems. Like any other technique or technology, it has use cases for which it shines and those in which it does not. Understanding the bounds of deep learning’s domain of application, the amount of data that it needs, and the computational costs of training and maintaining a deep learning model is key to successfully applying deep learning to your business. The realization that deep learning is not a fundamental necessity for solving every business problem can be freeing. But this doesn’t mean that deep learning isn’t at all useful, in fact it can be transformative. When applied to the right problems, deep learning can outshine traditional machine learning approaches by making sense of unstructured datasets like text, images, and video.
How Do I Get Started with Deep Learning?
If you’d like to explore the world of deep learning, three useful recommendations can provide a springboard for your journey: (1) understand deep learning is one of many tools, (2) find a trusted guide, and (3) put your learning to practice.
The first step in bolstering your knowledge of deep learning is to realize that it is one of many tools that can be used to solve a business problem. Understanding that deep learning has its limitations is just as important as realizing its applicability. Although deep models can capture non-linearity and have innate feature extraction capabilities, these attributes come with the cost of being data-hungry and computationally-expensive. While deep learning is a real and powerful thing, it should be used in an appropriate context to solve a specific problem.
A second step should be to find a trusted guide. It is much easier to navigate the vast world of deep learning with a person who has traveled there before. There are many online resources that provide self-paced learning through tutorials and examples. While these materials can provide fertile soil for those just starting out in the area of deep learning, these same resources can leave the more experienced learners with stunted growth and something more to be desired. Being able to ask questions, have a conversation, and observe best practices is an invaluable benefit of having a guide in your journey.
A third and final step is to practice what you have learned. Use frameworks like Keras and Tensorflow to build your first neural network. Explore adding layers with different node counts and activation functions. Test loading large and small datasets and making predictions with your models. You’ll be amazed at how some of the concepts you encounter will come to life when you put it into practice.
Jumpstart Your Learning
If you’d like to learn more about deep learning and neural networks, check out Enthought’s new course: Practical Deep Learning for Scientists and Engineers. This course covers the basic components that comprise neural networks and provides students with hands-on experience creating, training, and evaluating these types of machine learning models. Throughout the course, students will build an actionable understanding of deep learning concepts that go beyond neural networks and have implications in the larger machine learning ecosystem. By the end, you’ll have the skills and confidence needed to navigate the world of deep learning.
Enthought’s technical team is filled with experts who have served as data scientists, machine learning engineers, and computer scientists in a wide variety of scientific fields. We understand the complexities of providing innovative solutions while focusing on feasibility and practicality. We are passionate about developing the right solutions for the correct business problems. Often, this means evaluating and determining the right modeling approach regardless of marketplace popularity. Whether it’s a cutting-edge deep neural network or a traditional statistical model, we are confident that the solutions we provide are justified and fairly assessed. Sign up now to learn from one or our experienced trainers and begin your deep learning journey today.
About the Authors
Logan Thomas holds a M.S. in mechanical engineering with a minor in statistics from the University of Florida and a B.S. in mathematics from Palm Beach Atlantic University. Logan has worked as a data scientist and machine learning engineer in both the digital media and protective engineering industries. His experience includes discovering relationships in large datasets, synthesizing data to influence decision making, and creating/deploying machine learning models.
Eric Olsen holds a Ph.D. in history from the University of Pennsylvania, a M.S. in software engineering from Pennsylvania State University, and a B.A. in computer science from Utah State University. Eric spent three decades working in software development in a variety of fields, including atmospheric physics research, remote sensing and GIS, retail, and banking. In each of these fields, Eric focused on building software systems to automate and standardize the many repetitive, time-consuming, and unstable processes that he encountered.
Related Content
The Emergence of the AI Co-Scientist
The era of the AI Co-Scientist is here. How is your organization preparing?
Understanding Surrogate Models in Scientific R&D
Surrogate models are reshaping R&D by making research faster, more cost-effective, and more sustainable.
R&D Innovation in 2025
As we step into 2025, R&D organizations are bracing for another year of rapid-pace, transformative shifts.
Revolutionizing Materials R&D with “AI Supermodels”
Learn how AI Supermodels are allowing for faster, more accurate predictions with far fewer data points.
What to Look for in a Technology Partner for R&D
In today’s competitive R&D landscape, selecting the right technology partner is one of the most critical decisions your organization can make.
Digital Transformation vs. Digital Enhancement: A Starting Decision Framework for Technology Initiatives in R&D
Leveraging advanced technology like generative AI through digital transformation (not digital enhancement) is how to get the biggest returns in scientific R&D.
Digital Transformation in Practice
There is much more to digital transformation than technology, and a holistic strategy is crucial for the journey.
Leveraging AI for More Efficient Research in BioPharma
In the rapidly-evolving landscape of drug discovery and development, traditional approaches to R&D in biopharma are no longer sufficient. Artificial intelligence (AI) continues to be a...
Utilizing LLMs Today in Industrial Materials and Chemical R&D
Leveraging large language models (LLMs) in materials science and chemical R&D isn't just a speculative venture for some AI future. There are two primary use...
Top 10 AI Concepts Every Scientific R&D Leader Should Know
R&D leaders and scientists need a working understanding of key AI concepts so they can more effectively develop future-forward data strategies and lead the charge...